Computer Vision
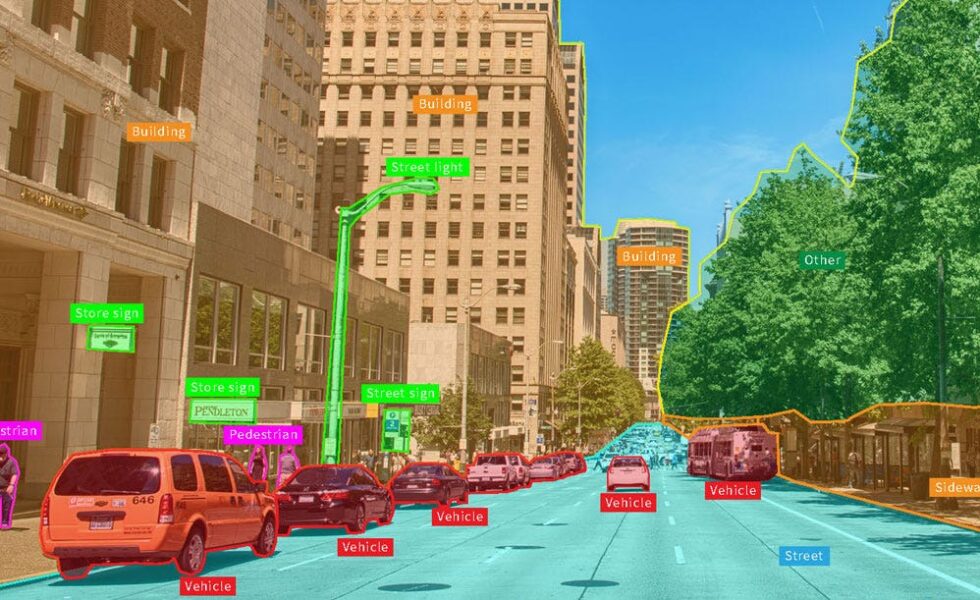
C2SMART’s innovative computer vision solutions leverage deep learning tailored to urban environments, enabling real-time object detection and tracking to improve mobility and safety for vehicles and vulnerable road users. By

Connected Cities with Smart Transportation
Read about alumni projects, successes, awards, projects, and events.
C2SMART’s innovative computer vision solutions leverage deep learning tailored to urban environments, enabling real-time object detection and tracking to improve mobility and safety for vehicles and vulnerable road users. By

ARISE provides an advanced STEM (Science, Technology, Engineering and Math) research opportunity to New York City students lacking access to high quality STEM education experiences.

How do we know whether a section of the roadway is at high safety risk?
Historically, the answer has been relatively straightforward: we count the number of crashes at that location over a period of time and compare it to other roadway sections. If the roadway section of our interest contains a high number of crashes, we then decide what can be done, if anything, to lower the number of crashes.
This method has been the go-to method for safety evaluation for decades, and with good reason. The number of crashes (or other crash-based safety measures) at a roadway section is a fairly straightforward piece of evidence regarding its relative safety risk level.
There’s only one problem with it, which is that in order to obtain this data, we have to wait for crashes to happen.
But, thanks to big data, there is a different way to do things.